Справочная информация о семействе видеокарт NV4X
Справочная информация о семействе видеокарт G7X
Справочная информация о семействе видеокарт G8X/G9X
Справочная информация о семействе видеокарт Tesla (GT2XX)
Справочная информация о семействе видеокарт Fermi (GF1XX)
Справочная информация о семействе видеокарт Kepler (GK1XX/GM1XX)
Справочная информация о семействе видеокарт Maxwell (GM2XX)
Справочная информация о семействе видеокарт Pascal (GP1XX)
Спецификации чипов семейства Pascal
| кодовое имя |
GP102 |
GP104 |
GP106 |
| базовая статья |
- |
здесь |
здесь |
| технология, нм |
16 |
| транзисторов, млрд |
12 |
7,2 |
4,4 |
| универсальных процессоров |
3584 |
2560 |
1280 |
| текстурных блоков |
224 |
160 |
80 |
| блоков блендинга |
96 |
64 |
48 |
| шина памяти |
384 |
256 |
192 |
| типы памяти |
GDDR5, GDDR5X |
| системная шина |
PCI Express 3.0 |
| интерфейсы |
DVI Dual Link
HDMI 2.0b
DisplayPort 1.4 |
| D3D Feature Level |
12_1 |
| точность вычислений |
FP32/FP64 |
Спецификации референсных карт на базе семейства Pascal
| карта |
чип |
блоков ALU/TMU/ROP |
частота ядра, МГц |
частота памяти, МГц |
объем памяти, ГБ |
ПСП, ГБ/c
(бит) |
текстури-
рование, Гтекс |
филлрейт, Гпикс |
TDP, Вт |
| Titan X |
GP102 |
3584/224/96 |
1417(1530) |
2500(10000) |
12 GDDR5X |
480 (384) |
336 |
144 |
250 |
| GeForce GTX 1080 |
GP104 |
2560/160/64 |
1607(1733) |
2500(10000) |
8 GDDR5X |
320 (256) |
257 |
103 |
180 |
| GeForce GTX 1070 |
GP104 |
1920/120/64 |
1506(1683) |
2000(8000) |
8 GDDR5 |
256 (256) |
181 |
96 |
150 |
| GeForce GTX 1060 |
GP106 |
1280/80/48 |
1506(1708) |
2000(8000) |
6 GDDR5 |
192 (192) |
121 |
72 |
120 |
Графический ускоритель GeForce GTX 1080
| Параметр |
Значение |
|---|
| Кодовое имя чипа |
GP104 |
| Технология производства |
16 нм FinFET |
| Количество транзисторов |
7,2 млрд. |
| Площадь ядра |
314 мм² |
| Архитектура |
Унифицированная, с массивом общих процессоров для потоковой обработки многочисленных видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX |
DirectX 12, с поддержкой уровня возможностей Feature Level 12_1 |
| Шина памяти |
256-битная: восемь независимых 32-битных контроллеров памяти с поддержкой GDDR5 и GDDR5X памяти |
| Частота графического процессора |
1607 (1733) МГц |
| Вычислительные блоки |
20 потоковых мультипроцессоров, включающих 2560 скалярных ALU
для расчетов с плавающей запятой в рамках стандарта IEEE 754–2008; |
| Блоки текстурирования |
160 блоков текстурной адресации и фильтрации с поддержкой FP16-
и FP32-компонент в текстурах и поддержкой трилинейной и анизотропной
фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) |
8 широких блоков ROP (64 пикселя) с поддержкой различных режимов
сглаживания, в том числе программируемых и при FP16- или FP32-формате
буфера кадра. Блоки состоят из массива конфигурируемых ALU и отвечают
за генерацию и сравнение глубины, мультисэмплинг и блендинг |
| Поддержка мониторов |
Интегрированная поддержка до четырех мониторов, подключенных
по интерфейсам Dual Link DVI, HDMI 2.0b и DisplayPort 1.2 (1.3/1.4
Ready) |
| Спецификации референсной видеокарты GeForce GTX 1080 |
|---|
| Параметр |
Значение |
|---|
| Частота ядра |
1607 (1733) МГц |
| Количество универсальных процессоров |
2560 |
| Количество текстурных блоков |
160 |
| Количество блоков блендинга |
64 |
| Эффективная частота памяти |
10000 (4×2500) МГц |
| Тип памяти |
GDDR5X |
| Шина памяти |
256-бит |
| Объем памяти |
8 ГБ |
| Пропускная способность памяти |
320 ГБ/с |
| Вычислительная производительность (FP32) |
около 9 терафлопс |
| Теоретическая максимальная скорость закраски |
103 гигапикселей/с |
| Теоретическая скорость выборки текстур |
257 гигатекселей/с |
| Шина |
PCI Express 3.0 |
| Разъемы |
Один разъем Dual Link DVI, один HDMI и три DisplayPort |
| Энергопотребление |
до 180 Вт |
| Дополнительное питание |
Один 8-контактный разъем |
| Число слотов, занимаемых в системном корпусе |
2 |
| Рекомендуемая цена |
$599–699 (США), 54990 руб (Россия) |
Новая модель видеокарты GeForce GTX 1080 получила логичное
для первого решения новой серий GeForce наименование — она отличается
от своего прямого предшественника только измененной цифрой поколения.
Новинка не просто заменяет в текущей линейке компании топовые решения,
но и на какое-то время стала флагманом новой серии, пока не выпустили
Titan X на GPU еще большей мощности. Ниже ее в иерархии располагается
также уже анонсированная модель GeForce GTX 1070, основанная
на урезанной версии чипа GP104, которую мы еще рассмотрим ниже.
Рекомендованные цены на новую видеоплату Nvidia составляют $599
и $699 для обычных версий и специального издания Founders Edition (см.
далее), соответственно, и это довольно неплохое предложение с учетом
того, что GTX 1080 опережает не только GTX 980 Ti, но и Titan X.
На сегодня новинка является лучшим по производительности решением
на рынке одночиповых видеокарт без каких-либо вопросов, и при этом она
стоит дешевле самых производительных видеокарт предыдущего поколения.
Пока конкурента от AMD у GeForce GTX 1080 по сути нет, поэтому в Nvidia
смогли установить такую цену, которая их устраивает.
Рассматриваемая видеокарта основана на чипе GP104, имеющем 256-битную
шину памяти, но новый тип памяти GDDR5X работает на весьма высокой
эффективной частоте в 10 ГГц, что дает высокую пиковую пропускную
способность в 320 ГБ/с — что почти на уровне GTX 980 Ti с 384-битной
шиной. Объем установленной на видеокарту памяти с такой шиной мог быть
равен 4 или 8 ГБ, но ставить меньший объем для столь мощного решения
в современных условиях было бы глупо, поэтому GTX 1080 совершенно
логично получила 8 ГБ памяти, и этого объема хватит для запуска любых
3D-приложений с любыми настройками качества на несколько лет вперед.
Печатная плата GeForce GTX 1080 по понятным причинам прилично
отличается от предыдущих PCB компании. Значение типичного
энергопотребления для новинки составляет 180 Вт — это несколько выше,
чем у GTX 980, но заметно ниже, чем у менее производительных Titan X
и GTX 980 Ti. Референсная плата имеет привычный набор разъемов
для присоединения устройств вывода изображения: один Dual-Link DVI, один
HDMI и три DisplayPort.
Референсный дизайн Founders Edition
Еще при анонсе GeForce GTX 1080 в начале мая было объявлено
специальное издание видеокарты под названием Founders Edition, имеющее
более высокую цену по сравнению с обычными видеокартами партнеров
компании. По сути, это издание является референсным дизайном карты
и системы охлаждения, и производится оно самой компанией Nvidia. Можно
по-разному относиться к таким вариантам видеокарт, но разработанный
инженерами компании референсный дизайн и произведенная с применением
качественных компонентов конструкция имеет своих поклонников.
А вот будут ли они отдавать на несколько тысяч рублей больше
за видеокарту от самой Nvidia — это вопрос, ответ на который может дать
только практика. В любом случае, поначалу в продаже появятся именно
референсные видеокарты от Nvidia по повышенной цене, и выбирать особенно
не из чего — так бывает при каждом анонсе, но референсная GeForce GTX
1080 отличается тем, что в таком виде ее планируется продавать на всем
протяжении срока ее жизни, вплоть до выхода решений следующего
поколения.
В Nvidia считают, что это издание имеет свои достоинства даже
перед лучшими произведениями партнеров. Например, двухслотовый дизайн
кулера позволяет с легкостью собирать на основе этой мощной видеокарты
как игровые ПК сравнительно небольшого форм-фактора, так и многочиповые
видеосистемы (даже несмотря на нерекомендуемый компанией режим работы
в трех- и четырехчиповом режиме). GeForce GTX 1080 Founders Edition
имеет некоторые преимущества в виде эффективного кулера с использованием
испарительной камеры и вентилятора, выбрасывающего нагретый воздух
из корпуса — это первое такое решение Nvidia, потребляющее менее 250 Вт
энергии.
По сравнению с предыдущими референсными дизайнами продуктов компании,
схема питания была модернизирована с четырехфазной до пятифазной.
В Nvidia говорят и об улучшенных компонентах, на которых основана
новинка, также были снижены электрические помехи, позволяющие улучшить
стабильность напряжения и разгонный потенциал. В результате всех
улучшений энергоэффективность референсной платы увеличилась на 6%
по сравнению с GeForce GTX 980.
А для того, чтобы отличаться от «обычных» моделей GeForce GTX 1080
и внешне, для Founders Edition разработали необычный «рубленый» дизайн
корпуса. Который, правда, наверняка привел также и к усложнению формы
испарительной камеры и радиатора (см. фото), что возможно и послужило
одним из поводов для доплаты в $100 за такое специальное издание.
Повторимся, что в начале продаж особого выбора у покупателей не будет,
но в дальнейшем можно будет выбрать как решение с собственным дизайном
от одного из партнеров компании, так и в исполнении самой Nvidia.
Новое поколение графической архитектуры Pascal
Видеокарта GeForce GTX 1080 стала первым решением компании на основе
чипа GP104, относящегося к новому поколению графической архитектуры
Nvidia — Pascal. Хотя новая архитектура взяла в основу решения,
отработанные еще в Maxwell, в ней есть и важные функциональные отличия,
о которых мы напишем далее. Главным же изменением с глобальной точки
зрения стал новый технологический процесс, по которому выполнен новый
графический процессор.
Применение техпроцесса 16 нм FinFET при производстве графических
процессоров GP104 на фабриках тайваньской компании TSMC дало возможность
значительно повысить сложность чипа при сохранении сравнительно
невысокой площади и себестоимости. Сравните количество транзисторов
и площадь чипов GP104 и GM204 — они близки по площади (кристалл новинки
даже чуть меньше физически), но чип архитектуры Pascal имеет заметно
большее количество транзисторов, а соответственно и исполнительных
блоков, в том числе обеспечивающих новую функциональность.
С архитектурной точки зрения, первый игровой Pascal весьма похож
на аналогичные решения архитектуры Maxwell, хотя есть и некоторые
отличия. Как и Maxwell, процессоры архитектуры Pascal будут иметь разную
конфигурацию вычислительных кластеров Graphics Processing Cluster
(GPC), потоковых мультипроцессоров Streaming Multiprocessor (SM)
и контроллеров памяти. Мультипроцессор SM — это высокопараллельный
мультипроцессор, который планирует и запускает варпы (warp, группы из 32
потоков команд) на CUDA-ядрах и других исполнительных блоках
в мультипроцессоре. Подробные данные об устройстве всех этих блоков вы
можете найти в наших обзорах предыдущих решений компании Nvidia.
Каждый из мультипроцессоров SM спарен с движком PolyMorph Engine,
который обрабатывает текстурные выборки, тесселяцию, трансформацию,
установку вершинных атрибутов и коррекцию перспективы. В отличие
от предыдущих решений компании, PolyMorph Engine в чипе GP104 также
содержит новый блок мультипроецирования Simultaneous Multi-Projection,
о котором мы еще поговорим ниже. Комбинация мультипроцессора SM с одним
движком Polymorph Engine традиционно для Nvidia называется TPC — Texture
Processor Cluster.

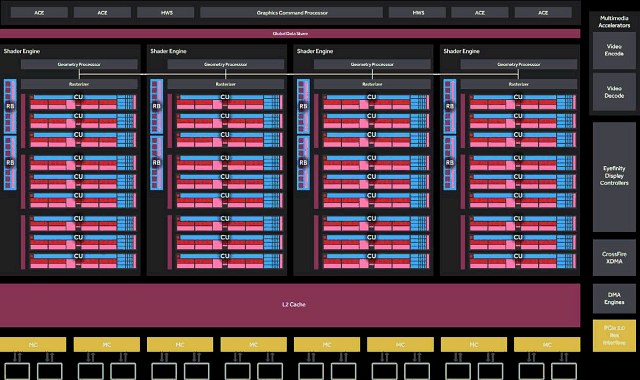
Всего чип GP104 в составе GeForce GTX 1080 содержит четыре кластера
GPC и 20 мультипроцессоров SM, а также восемь контроллеров памяти,
объединенных с блоками ROP в количестве 64 штук. Каждый кластер GPC
имеет выделенный движок растеризации и включает в себя пять
мультипроцессоров SM. Каждый мультипроцессор, в свою очередь, состоит
из 128 CUDA-ядер, 256 КБ регистрового файла, 96 КБ разделяемой памяти,
48 КБ кэш-памяти первого уровня и восьми текстурных блоков TMU. То есть,
всего в GP104 содержится 2560 CUDA-ядер и 160 блоков TMU.
Также графический процессор, на котором основана видеокарта GeForce
GTX 1080, содержит восемь 32-битных (в отличие от 64-битных,
применяющихся ранее) контроллеров памяти, что дает нам итоговую
256-битную шину памяти. К каждому из контроллеров памяти привязано
по восемь блоков ROP и 256 КБ кэш-памяти второго уровня. То есть, всего
чип GP104 содержит 64 блоков ROP и 2048 КБ кэш-памяти второго уровня.
Благодаря архитектурным оптимизациям и новому техпроцессу, первый
игровой Pascal стал самым энергоэффективным графическим процессором
за все время. Причем, вклад в это есть как со стороны одного из самых
совершенных технологических процессов 16 нм FinFET, так и от проведенных
оптимизаций архитектуры в Pascal, по сравнению с Maxwell. В Nvidia
смогли повысить тактовую частоту даже больше, чем они рассчитывали
при переходе на новый техпроцесс. GP104 работает на более высокой
частоте, чем работал бы гипотетический GM204, выпущенный при помощи
техпроцесса 16 нм. Для этого инженерам Nvidia пришлось тщательно
проверить и оптимизировать все узкие места предыдущих решений, не дающие
разогнаться выше определенного порога. В результате, новая модель
GeForce GTX 1080 работает более чем на 40% повышенной частоте,
по сравнению с GeForce GTX 980. Но это еще не все изменения, связанные
с частотой работы GPU.
Технология GPU Boost 3.0
Как мы хорошо знаем по предыдущим видеокартам компании Nvidia,
в своих графических процессорах они применяют аппаратную технологию GPU
Boost, предназначенную для увеличения рабочей тактовой частоты GPU
в режимах, когда он еще не достиг пределов по энергопотреблению
и тепловыделению. За прошедшие годы этот алгоритм претерпел множество
изменений, и в видеочипе архитектуры Pascal применяется уже третье
поколение этой технологии — GPU Boost 3.0, основным нововведением
которого стала более тонкая установка турбо-частот, в зависимости
от напряжения.
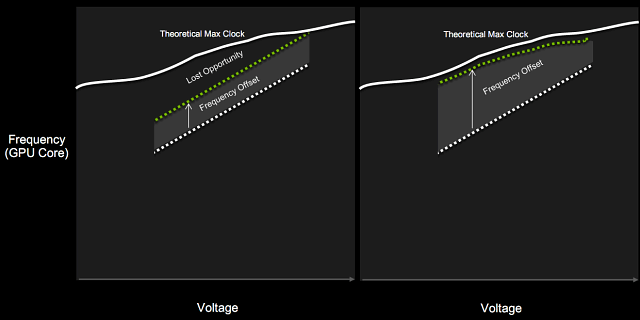
Если вы вспомните принцип работы предыдущих версий технологии,
то разница между базовой частотой (гарантированное минимальное значение
частоты, ниже которого GPU не опускается, как минимум в играх)
и турбо-частотой была фиксированной. То есть, турбо-частота всегда была
на определенное количество мегагерц выше базовой. В GPU Boost 3.0
появилась возможность установки смещений турбо-частот для каждого
напряжения по отдельности. Проще всего это понять по иллюстрации:
Слева указан GPU Boost второй версии, справа — третьей, появившейся
в Pascal. Фиксированная разница между базовой и турбо-частотами
не давала раскрыть возможности GPU полностью, в некоторых случаях
графические процессоры предыдущих поколений могли работать быстрее
на установленном напряжении, но фиксированное превышение турбо-частоты
не давало сделать этого. В GPU Boost 3.0 такая возможность появилась,
и турбо-частота может устанавливаться для каждого из индивидуальных
значений напряжения, полностью выжимая все соки из GPU.
Для того, чтобы управлять разгоном и установить кривую турбо-частоты,
требуются удобные утилиты. Сама Nvidia этим не занимается, но помогает
своим партнерам создать подобные утилиты для облегчений разгона
(в разумных пределах, конечно). К примеру, новые функциональные
возможности GPU Boost 3.0 уже раскрыты в EVGA Precision XOC, включающей
специальные сканер разгона, автоматически находящий и устанавливающий
нелинейную разницу между базовой частотой и турбо-частотой для разных
значений напряжения при помощи запуска встроенного теста
производительности и стабильности. В результате у пользователя
получается кривая турбо-частоты, идеально соответствующая возможностям
конкретного чипа. Которую, к тому же, можно как угодно модифицировать
в ручном режиме.
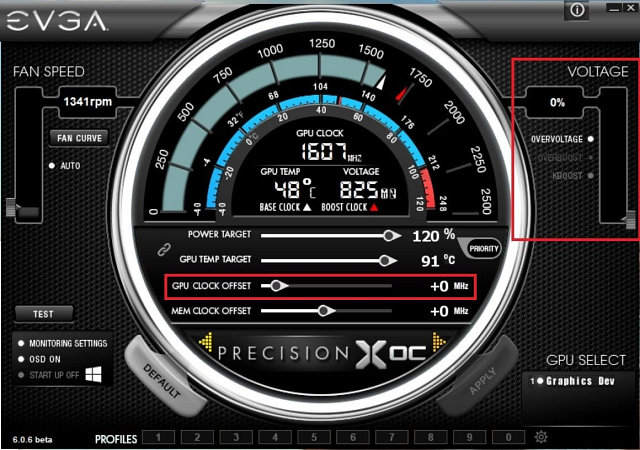
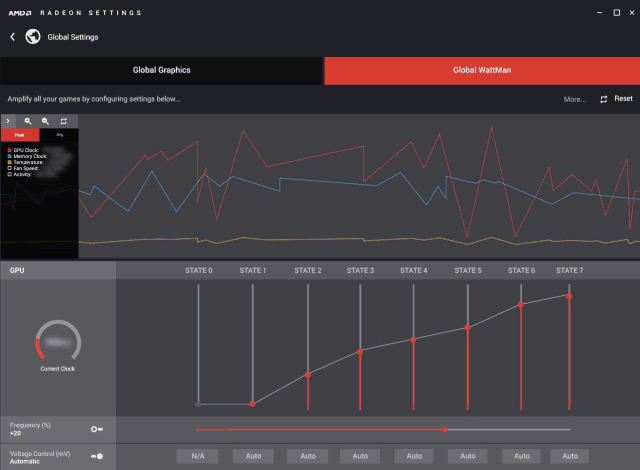
Как вы видите на скриншоте утилиты, в дополнение к информации о GPU
и системе, есть также настройки для разгона: Power Target (определяет
типичное энергопотребление при разгоне, в процентах от стандартного),
GPU Temp Target (максимально допустимая температура ядра), GPU Clock
Offset (превышение над базовой частотой для всех значений напряжения),
Memory Offset (превышение частоты видеопамяти над значением
по умолчанию), Overvoltage (дополнительная возможность для повышения
напряжения).
Утилита Precision XOC включает три режима разгона: основной Basic,
линейный Linear и ручной Manual. В основном режиме можно установить
единое значение превышения частоты (фиксированную турбо-частоту)
над базовой, как это было для предыдущих GPU. Линейный режим позволяет
установить линейное изменение частоты от минимального до максимального
значений напряжения для GPU. Ну и в ручном режиме можно выставить
уникальные значения частоты GPU для каждой точки напряжения на графике.
В составе утилиты есть также специальный сканер для автоматического
разгона. Можно или установить собственные уровни частоты или позволить
утилите Precision XOC просканировать GPU на всех напряжениях и найти
максимально стабильные частоты для каждой точки на кривой напряжения
и частоты полностью автоматически. В процессе сканирования Precision XOC
постепенно добавляет частоту GPU и проверяет его работу на стабильность
или появление артефактов, строя идеальную кривую частот и напряжений,
которая будет уникальна для каждого конкретного чипа.
Этот сканер можно настроить под свои собственные требования, задав
временной отрезок тестирования каждого значения напряжения, минимум
и максимум проверяемой частоты, и ее шаг. Понятно, что для достижения
стабильных результатов лучше будет выставить небольшой шаг и приличную
продолжительность тестирования. В процессе тестирования может
наблюдаться нестабильная работа видеодрайвера и системы, но если сканер
не зависнет, то восстановит работу и продолжит нахождение оптимальных
частот.
Новый тип видеопамяти GDDR5X и улучшенное сжатие
Итак, мощность графического процессора заметно выросла, а шина памяти
осталась всего лишь 256-битной — не будет ли пропускная способность
памяти ограничивать общую производительность и что с этим можно делать?
Похоже, что перспективная HBM-память второго поколения все еще слишком
дорога в производстве, поэтому пришлось искать другие варианты. Еще
с момента появления GDDR5-памяти в 2009 году, инженеры компании Nvidia
исследовали возможности использования новых типов памяти. В результате,
разработки пришли к внедрению нового стандарта памяти GDDR5X — самого
сложного и продвинутого на сегодняшний момент стандарта, дающего
скорость передачи 10 Gbps.
Nvidia приводит интересный пример того, насколько это быстро.
Между переданными битами проходит всего 100 пикосекунд — за такое время
луч света пройдет расстояние всего лишь в один дюйм (около 2,5 см).
И при использовании GDDR5X-памяти цепи приема-передачи данных должны
менее чем за половину этого времени выбрать значение переданного бита,
до того, как будет прислан следующий — это просто чтобы вы понимали,
до чего дошли современные технологии.
Чтобы добиться такой скорости работы, потребовалась разработка новой
архитектуры системы ввода-вывода данных, потребовавшей нескольких лет
совместной разработки с производителями чипов памяти. Кроме возросшей
скорости передачи данных, выросла и энергоэффективность — чипы памяти
стандарта GDDR5X используют пониженное напряжение в 1,35 В и произведены
по новым технологиям, что дает то же потребление энергии при на 43%
большей частоте.
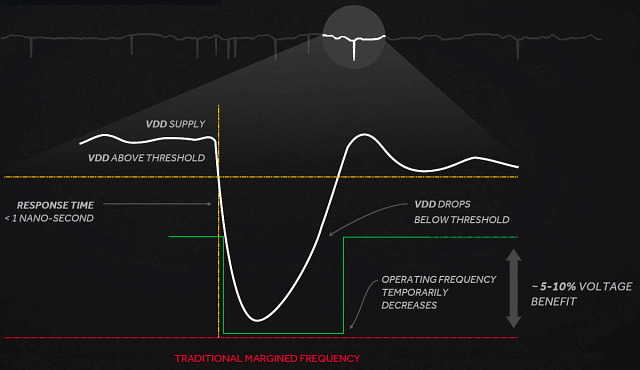
Инженерам компании пришлось перерабатывать линии передачи данных
между ядром GPU и чипами памяти, больше внимания обращать
на предотвращение потери и деградацию сигнала на всем пути от памяти
к GPU и обратно. Так, на приведенной выше иллюстрации показан
захваченный сигнал в виде большого симметричного «глаза», что говорит
о хорошей оптимизации всей цепи и относительной легкости захвата данных
из сигнала. Причем, описанные выше изменения привели не только
к возможности применения GDDR5X на 10 ГГц, но также и должны помочь
получить высокую ПСП на будущих продуктах, использующих более привычную
GDDR5-память.
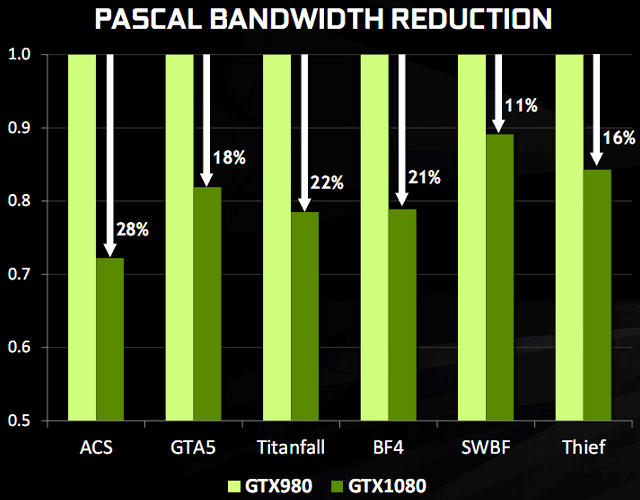
Хорошо, более чем 40% прироста в ПСП от применения новой памяти мы
получили. Но не маловато ли этого? Для дальнейшего увеличения
эффективности использования полосы пропускания памяти в Nvidia
продолжили улучшать внедренное еще в предыдущих архитектурах продвинутое
сжатие данных. Подсистема памяти в GeForce GTX 1080 использует
улучшенные и несколько новых техник по сжатию данных без потерь,
предназначенные для снижения требований к ПСП — уже четвертое поколение
внутричипового сжатия.
Алгоритмы сжатия данных в памяти приносят сразу несколько
положительных моментов. Сжатие снижает количество записываемых данных
в память, то же самое касается данных, пересылаемых из видеопамяти
в кэш-память второго уровня, что улучшает эффективность использования
L2-кэша, так как сжатый тайл (блок из нескольких пикселей фреймбуфера)
имеет меньший размер, чем несжатый. Также уменьшается количество данных,
пересылаемых между разными точками, вроде текстурного модуля TMU
и фреймбуфера.
Конвейер сжатия данных в GPU использует несколько алгоритмов, которые
определяются в зависимости от «сжимаемости» данных — для них
подбирается лучший из имеющихся алгоритмов. Одним из самых важных
является алгоритм дельта-кодирования данных о цвете пикселей (delta
color compression). Этот способ сжатия кодирует данные в виде разницы
между последовательными значениями вместо самих данных. GPU вычисляет
разницу в цветовых значениях между пикселями в блоке (тайле) и сохраняет
блок как некий усредненный цвет для всего блока плюс данные о разнице
в значениях для каждого пикселя. Для графических данных такой метод
обычно хорошо подходит, так как цвет в пределах небольших тайлов
для всех пикселей зачастую отличается не слишком сильно.

Графический процессор GP104 в составе GeForce GTX 1080 поддерживает
большее количество алгоритмов сжатия по сравнению с предыдущими чипами
архитектуры Maxwell. Так, алгоритм сжатия 2:1 стал более эффективным,
а в дополнение к нему появились два новых алгоритма: режим сжатия 4:1,
подходящий для случаев, когда разница в значении цвета пикселей блока
очень невелика, и режим 8:1, сочетающий алгоритм постоянного сжатия
с соотношением 4:1 блоков размером 2×2 пикселя с двукратным сжатием
дельты между блоками. Когда сжатие совсем невозможно, оно
не используется.
Впрочем, в реальности последнее бывает весьма нечасто. В этом можно
убедиться по примерам скриншотов из игры Project CARS, которые привела
Nvidia чтобы проиллюстрировать повышенную степень сжатия в Pascal.
На иллюстрациях пурпурным закрашены те тайлы кадрового буфера, которые
смог сжать графический процессор, а не поддающиеся сжатию без потерь
остались с оригинальным цветом (сверху — Maxwell, снизу — Pascal).
Как видите, новые алгоритмы сжатия в GP104 действительно работают
гораздо лучше, чем в Maxwell. Хотя старая архитектура также смогла сжать
большинство тайлов в сцене, большое количество травы и деревьев
по краям, а также детали машины не подвергаются устаревшим алгоритмам
сжатия. Но при включении в работу новых техник в Pascal, несжатым
осталось очень небольшое количество участков изображения — улучшенная
эффективность налицо.
В результате улучшений в сжатии данных, GeForce GTX 1080 способен
значительно снизить количество пересылаемых данных в каждом кадре. Если
говорить о цифрах, то улучшенное сжатие экономит дополнительно около 20%
эффективной полосы пропускания памяти. В дополнение к более чем на 40%
повышенной ПСП у GeForce GTX 1080 относительно GTX 980 от использования
GDDR5X-памяти, все вместе это дает около 70% прироста в эффективном ПСП,
по сравнению с моделью прошлого поколения.
Поддержка асинхронных вычислений Async Compute
Большинство современных игр используют сложные вычисления
в дополнение к графическим. К примеру, вычисления при расчете поведения
физических тел вполне можно проводить не до или после графических
вычислений, а одновременно с ними, так как они не связаны друг с другом
и не зависят друг от друга в пределах одного кадра. Также в пример можно
привести постобработку уже отрендеренных кадров и обработку
аудиоданных, которые тоже можно исполнять параллельно с рендерингом.
Еще одним ярким примером использования функциональности служит
техника асинхронного искажения времени (Asynchronous Time Warp),
используемая в системах виртуальной реальности для того, чтобы изменить
выдаваемый кадр в соответствии с движением головы игрока прямо
перед самым его выводом, прерывая рендеринг следующего. Подобная
асинхронная загрузка мощностей GPU позволяет повысить эффективность
использования его исполнительных блоков.
Подобные нагрузки создают два новых сценария использования GPU.
Первый из них включает накладывающиеся загрузки, так как многие типы
задач не используют возможности графических процессоров полностью,
и часть ресурсов простаивает. В таких случаях можно просто запустить
на одном GPU две разные задачи, разделяющие его исполнительные блоки
для получения более эффективного использования — например,
PhysX-эффекты, выполняющиеся совместно с 3D-рендерингом кадра.
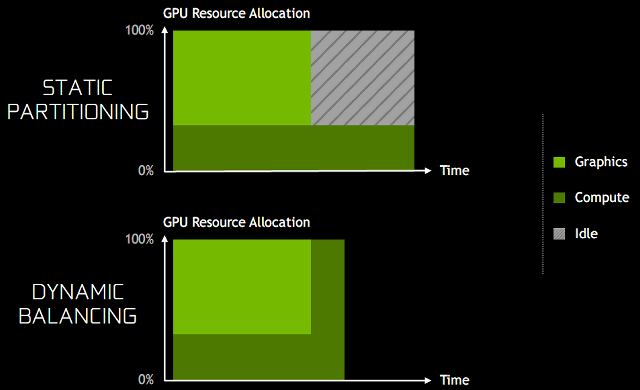
Для улучшения работы этого сценария, в архитектуре Pascal появилась
динамическая балансировка загрузки (dynamic load balancing).
В предыдущей архитектуре Maxwell перекрывающиеся нагрузки были выполнены
в виде статического распределения ресурсов GPU на графические
и вычислительные. Такой подход эффективен при условии, что баланс
между двумя нагрузками примерно соответствует разделению ресурсов
и задачи выполняются одинаково по времени. Если же неграфические
вычисления выполняются дольше графических, и обе ожидают завершения
общей работы, то часть GPU оставшееся время будет простаивать,
что вызовет снижение общей производительности и сведет всю выгоду
на нет. Аппаратная динамическая балансировка загрузки же позволяет
использовать освободившиеся ресурсы GPU сразу же как они станут
доступными — для понимания приведем иллюстрацию.
Существуют и задачи, критичные к времени исполнения, и это — второй
сценарий асинхронных вычислений. Например, исполнение алгоритма
асинхронного искажения времени в VR должно завершиться до развертки
(scan out) или кадр будет отброшен. В таком случае, GPU должен
поддерживать очень быстрое прерывание задачи и переключение на другую,
чтобы снять менее критическую задачу с исполнения на GPU, освободив его
ресурсы для критически важных задач — это называется preemption.
Одна команда рендеринга от игрового движка может содержать сотни
вызовов функций отрисовки, каждый вызов draw call, в свою очередь,
содержит сотни обрабатываемых треугольников, каждый из которых содержит
сотни пикселей, которые нужно рассчитать и отрисовать. В традиционном
подходе на GPU используется прерывание задач только на высоком уровне,
и графический конвейер вынужден ждать завершения всей этой работы
перед переключением задачи, что в результате приводит к очень большим
задержкам.
Чтобы исправить это, в архитектуре Pascal впервые была введена
возможность прерывания задачи на пиксельном уровне — Pixel Level
Preemption. Исполнительные блоки графического процессора Pascal могут
постоянно отслеживать прогресс выполнения задач рендеринга, и когда
прерывание будет запрошено, они могут остановить исполнение, сохранив
контекст для дальнейшего завершения, быстро переключившись на другую
задачу.
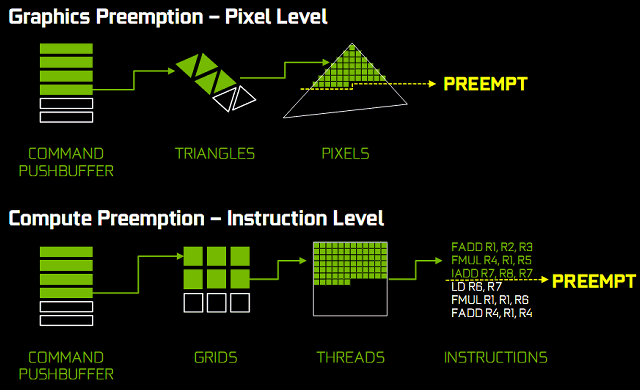
Прерывание и переключение на уровне потока для вычислительных
операций работает аналогично прерыванию на пиксельном уровне
для графических вычислений. Вычислительные нагрузки состоят
из нескольких сеток, каждая из которых содержит множество потоков. Когда
получен запрос на прерывание, выполняемые на мультипроцессоре потоки
заканчивают исполнение. Другие блоки сохраняют собственное состояние
чтобы продолжить с того же момента в дальнейшем, и GPU переключается
на другую задачу. Весь процесс переключения задач занимает менее чем
100 микросекунд после того, как выполняемые потоки завершают работу.
Для игровых нагрузок, сочетание прерываний на пиксельном уровне
для графических, и прерывания на уровне потоков для вычислительных задач
дает графическим процессорам архитектуры Pascal возможность быстрого
переключения между задачами с минимальными потерями времени.
А для вычислительных задач на CUDA, также возможно прерывание
с минимальной гранулярностью — на уровне инструкций. В таком режиме все
потоки останавливают выполнение сразу, немедленно переключаясь на другую
задачу. Этот подход требует сохранения большего количества информации
о состоянии всех регистров каждого потока, но в некоторых случаях
неграфических вычислений он вполне оправдан.
Использование быстрого прерывания и переключения задач в графических
и вычислительных задачах было добавлено в архитектуру Pascal для того,
чтобы графические и неграфические задачи могли прерываться на уровне
отдельных инструкций, а не целых потоков, как было в Maxwell и Kepler.
Эти технологии способны улучшить асинхронное исполнение различных
нагрузок на графический процессор и улучшить отзывчивость
при одновременном выполнении нескольких задач. На мероприятии Nvidia
показывали демонстрацию работы асинхронных вычислений на примере
вычисления физических эффектов. Если без асинхронных вычислений
производительность была на уровне 77–79 FPS, то с включением этих
возможностей частота кадров выросла до 93–94 FPS.
Мы уже приводили в пример одну из возможностей применения этой
функциональности в играх в виде асинхронного искажения времени в VR.
На иллюстрации показана работа этой технологии с традиционным
прерыванием (preemption) и с быстрым. В первом случае, процесс
асинхронного искажения времени стараются выполнить как можно позднее,
но до начала обновления изображения на дисплее. Но работа алгоритма
должна быть отдана на исполнение в GPU несколькими миллисекундами ранее,
так как без быстрого прерывания нет возможности точно выполнить работу
в нужный момент, и GPU простаивает некоторое время.

В случае точного прерывания на уровне пикселей и потоков
(на иллюстрации справа), такая возможность дает большую точность
в определении момента прерывания, и асинхронное искажение времени может
быть запущено значительно позже с уверенностью в завершении работы
до начала обновления информации на дисплее. А простаивающий некоторое
время в первом случае GPU можно загрузить какой-то дополнительной
графической работой.
Технология мультипроецирования Simultaneous Multi-Projection
В новом графическом процессоре GP104 появилась поддержка новой
технологии мультипроецирования (Simultaneous Multi-Projection — SMP),
позволяющей GPU отрисовывать данные на современных системах вывода
изображения более эффективно. SMP позволяет видеочипу одновременно
выводить данные в несколько проекций, для чего потребовалось ввести
новый аппаратный блок в GPU в состав движка PolyMorph в конце
геометрического конвейера перед блоком растеризации. Этот блок отвечает
за работу с несколькими проекциями для единого потока геометрии.
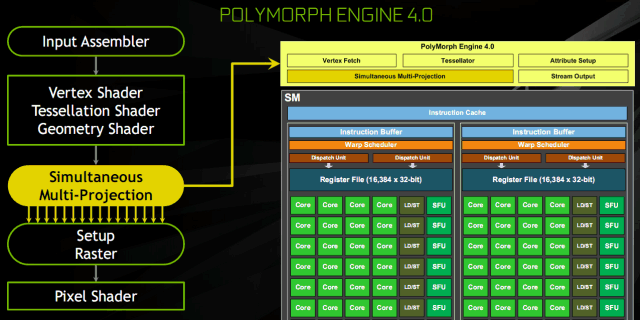
Движок мультипроецирования обрабатывает геометрические данные
одновременно для 16 заранее сконфигурированных проекций, объединяющих
точку проекции (камеры), эти проекции можно независимо вращать
или наклонять. Так как каждый геометрический примитив может появиться
одновременно в нескольких проекциях, движок SMP обеспечивает такую
функциональность, позволяя приложению дать инструкции видеочипу
для репликации геометрии до 32 раз (16 проекций при двух центрах
проецирования) без дополнительной обработки.
Весь процесс обработки аппаратно ускорен, и так
как мультипроецирование работает после геометрического движка, ему
не нужно повторять несколько раз все стадии обработки геометрии.
Сэкономленные ресурсы важны в условиях ограничения скорости рендеринга
производительностью обработки геометрии, вроде тесселяции, когда одна
и та же геометрическая работа выполняется несколько раз для каждой
проекции. Соответственно, в пиковом случае, мультипроецирование может
сократить необходимость в обработке геометрии до 32 раз.
Но зачем все это нужно? Есть несколько хороших примеров, где
технология мультипроецирования может быть полезной. Например,
многомониторная система из трех дисплеев, установленных под углом друг
к другу достаточно близко к пользователю (surround-конфигурация).
В типичной ситуации сцена отрисовывается в одной проекции, что приводит
к геометрическим искажениям и неверной отрисовке геометрии. Правильным
путем является три разных проекции для каждого из мониторов,
в соответствии с углом, под которым они расположены.
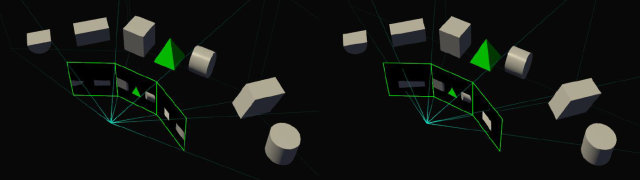
При помощи видеокарты на чипе с архитектурой Pascal это можно сделать
за один проход геометрии, указав три разные проекции, каждая для своего
монитора. И пользователь, таким образом, сможет менять угол,
под которым расположены мониторы друг к другу не только физически,
но и виртуально — поворачивая проекции для боковых мониторов, чтобы
получить корректную перспективу в 3D-сцене при заметно более широком
угле обзора (FOV). Правда, тут есть ограничение — для такой поддержки
приложение должно уметь отрисовывать сцену с широким FOV и использовать
специальные вызовы SMP API для его установки. То есть, в каждой игре так
не сделаешь, нужна специальная поддержка.
В любом случае, времена одной проекции на единственный плоский
монитор прошли, теперь много многомониторных конфигураций и изогнутых
дисплеев, на которых также можно применять эту технологию. Не говоря уже
о системах виртуальной реальности, которые используют специальные линзы
между экранами и глазами пользователя, что требует новых техник
проецирования 3D-изображения в 2D-картинку. Многие из таких технологий
и техник еще в начале разработки, главное, что старые GPU не могут
эффективно использовать более чем одну плоскую проекцию.